
SQL Server - Interview Questions
1.
What are the two authentication modes in SQL Server?
Two authentication modes in SQL Server are:
Windows Mode
Mixed Mode
2.
What are the differences between local and global temporary tables?
These local and global temporary tables are physical tables created within the Temporary Tables folder in tempdb database.
Local temporary table name is prefixed with hash ("#") sign.
Local temporary tables are visible only in the current session, i.e; are only available to the current connection for the user. These tables are deleted or destroyed after the user disconnects from the instance of SQL Server.
Global temporary table name is prefixed with a double hash ("##") sign.
Global temporary tables are visible to all sessions and all users. Global temporary tables are deleted or dropped when all users referencing the table disconnect from the instance of SQL Server.
Global temporary tables are dropped automatically when the last session using the temporary table has completed.
Temporary tables are automatically dropped when they go out of scope, unless they are explicitly dropped using DROP TABLE.
Example of Local temporary table
CREATE TABLE #tmp_local (id int, name varchar(50)) INSERT INTO #tmp_local VALUES (1, 'AAA'); SELECT * FROM #tmp_localExample of Global temporary table
CREATE TABLE ##tmp_global (id int, name varchar(50)) INSERT INTO ##tmp_global VALUES (1, 'AAA'); SELECT * FROM ##tmp_global
Also see:
Microsoft SQL Server Interview Questions By Chandan Sinha
3.
What is sub query and its properties?
A sub-query is a query which can be nested inside a main query like Select, Update, Insert or Delete statements. This can be used when expression is allowed.
Properties of sub query can be defined as
A sub query should not have order by clause.
A sub query should be placed in the right hand side of the comparison operator of the main query.
A sub query should be enclosed in parenthesis because it needs to be executed first before the main query.
More than one sub query can be included.
Types of sub query
There are three types of sub query –
Single row sub query which returns only one row.
Multiple row sub query which returns multiple rows.
Multiple column sub query which returns multiple columns to the main query. With that sub query result, Main query will be executed.
[Source]
4.
What is COALESCE in SQL Server?
COALESCE returns first non-null expression within the arguments. This function is used to return a non-null from more than one column in the arguments.
Example 1 of COALESCE
Select * from Students
Select ID, COALESCE(First_Name, Middle_Name, Last_Name) from Students
Result of running the above two queries:
| ID | First_Name | Middle_Name | Last_Name |
|---|---|---|---|
| 1 | John | NULL | NULL |
| 2 | NULL | William | NULL |
| 3 | NULL | NULL | Smith |
| 4 | Peter | Mark | Garcia |
| 5 | NULL | NULL | Campbell |
| ID | (No column name) |
|---|---|
| 1 | John |
| 2 | William |
| 3 | Smith |
| 4 | Peter |
| 5 | Campbell |
Example 2 of COALESCE
Select COALESCE(1, 2, 3, 4, 5, NULL)
| (No Column Name) |
|---|
| 1 |
Select COALESCE(Null, Null, Null, 4, 5, NULL)
| (No Column Name) |
|---|
| 4 |
5.
How to get the version of SQL Server?
Select SERVERPROPERTY('productversion')
6.
What is Normalization?
Goal of Normalization
When you normalize a database, you have four goals: arranging data into logical groupings such that each group describes a small part of the whole; minimizing the amount of duplicate data stored in a database; organizing the data such that, when you modify it, you make the change in only one place; and building a database in which you can access and manipulate the data quickly and efficiently without compromising the integrity of the data in storage.
Data normalization helps you design new databases to meet these goals or to test databases to see whether they meet the goals. Sometimes database designers refer to these goals in terms such as data integrity, referential integrity, or keyed data access. Ideally, you normalize data before you create database tables. However, you can also use these techniques to test an existing database. [Source]
A database is in first normal form if it satisfies the following conditions:
Contains only atomic values that is there must be only one field for each item of data you want to include.
Below table is not in first normal form:
| Furniture_ID | Furniture_Type | Price |
|---|---|---|
| 1 | Chair, Sofa | 300 |
| 2 | Table | 100 |
| 3 | Chair | 50 |
| 4 | Table, Chair | 200 |
| 5 | Sofa | 150 |
In order to normalize the above table to first normal form, above table is divided into two tables as below:
| Furniture_ID | Price |
|---|---|
| 1 | 300 |
| 2 | 100 |
| 3 | 50 |
| 4 | 200 |
| 5 | 150 |
| Furniture_ID | Furniture_Type |
|---|---|
| 2 | Table |
| 3 | Chair |
| 5 | Sofa |
A database is in second normal form if it satisfies the following conditions:
- is in 1st normal form
- all the keys are dependent on the whole of the key
| Furniture_ID | Furniture_Store_ID | Furniture_Store_Location |
|---|---|---|
| 1 | 1 | India |
| 2 | 2 | US |
| 3 | 1 | India |
| 4 | 3 | UK |
This above table has a composite primary key [Furniture_ID, Furniture_Store_ID]. The non-key attribute is [Furniture_Store_Location]. In this case, [Furniture_Store_Location] only depends on [Furniture_Store_ID], which is only part of the primary key. Therefore, this table does not satisfy second normal form. So it is divided into below two tables to normalize it into second normal form.
| Furniture_ID | Furniture_Store_ID |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 1 |
| 4 | 3 |
| Furniture_Store_ID | Furniture_Store_Location |
|---|---|
| 1 | India |
| 2 | US |
| 3 | UK |
A database is in third normal form if it satisfies the following conditions:
-if it is in second normal form
-It has no non-key dependencies (means there are no fields that are dependent on other fields that are not part of the key)
| Booking_ID | Location_ID | Location | Price |
|---|---|---|---|
| 1 | 2 | Singapore | 987 |
| 2 | 1 | Hong Kong | 654 |
| 3 | 2 | Singapore | 345 |
| 4 | 3 | Chile | 657 |
| 5 | 1 | Hong Kong | 700 |
In the table above, [Booking_ID] determines [Location_ID], and [Location_ID] determines [Location]. Therefore, [Booking_ID] determines [Location] via [Location_ID] and we have transitive functional dependency, and this structure does not satisfy third normal form. So the above table is normalized to third normal form and divided into two below tables.
| Booking_ID | Location_ID | Price |
|---|---|---|
| 1 | 2 | 987 |
| 2 | 1 | 654 |
| 3 | 2 | 345 |
| 4 | 3 | 657 |
| 5 | 1 | 700 |
| Location_ID | Location |
|---|---|
| 1 | Hong Kong |
| 2 | Singapore |
| 3 | Chile |
7.
How is ACID property related to Database?
Atomicity - a transaction to transfer funds from one account to another involves making a withdrawal operation from the first account and a deposit operation on the second. If the deposit operation failed, you don’t want the withdrawal operation to happen either.
Consistency - a database tracking a checking account may only allow unique check numbers to exist for each transaction.
Isolation - a teller looking up a balance must be isolated from a concurrent transaction involving a withdrawal from the same account. Only when the withdrawal transaction commits successfully and the teller looks at the balance again will the new balance be reported.
Durability - A system crash or any other failure must not be allowed to lose the results of a transaction or the contents of the database. Durability is often achieved through separate transaction logs that can "re-create" all transactions from some picked point in time (like a backup). [Source]
8.
What is a Stored Procedure?
A stored procedure groups one or more T-SQL statements into a logical unit, stored as an object in a SQL Server database. After stored procedure is created, its definition is stored in the sys.sql_module system catalog view. [SQL Server 2005 T-SQL Recipes: A Problem-Solution Approach by Joseph Sack]
Example 1 of Stored Procedure:
CREATE PROCEDURE AddTwoNumbers @num1 int=0, @num2 int=0, @result int OUTPUT AS BEGIN SET NOCOUNT ON; SELECT @result=@num1 + @num2 END GO DECLARE @i INT EXECUTE AddTwoNumbers 3,2,@i OUTPUT SELECT @iResult of running the above stored procedure:
| (No column name) |
|---|
| 5 |
Example 2 of Stored Procedure:
Select * from A
| ID | Name |
|---|---|
| 1 | A |
| 2 | A |
| 3 | A |
Two procedures are there: A_details and A_insert_row:
Create Procedure A_details
As
Begin
Select * from A
End
--Run the procedure on SQL Server:
Execute A_details
Create Procedure A_insert_row
(@ID int, @Name nchar(10))
As
Begin
Insert Into A
Values (@ID, @Name)
End
Execute A_insert_row 4,'B'
| ID | Name |
|---|---|
| 1 | A |
| 2 | A |
| 3 | A |
| 4 | B |
More on Stored Procedures:
Stored Procedures
Reasons for using stored procedures
9.
How stored procedures help reduce the Network Traffic?
You can reduce the amount of extraneous information sent back by a stored procedure (for example, the message N rows affected) by placing the following statement at the top of your stored procedure:
SET NO COUNT ON
When you use the Set NOCOUNT ON statement, you limit the amount of extraneous information sent back to the calling process, thus reducing network traffic and increasing performance. The following example, created in the pubs database, shows how to use the statement in a stored procedure:
Create procedure usp_nocount as SET NOCOUNT ON Select * from authors[Source: Microsoft SQL Server DBA Survival Guide]
10.
What is an Index?
Indexes are created on columns in tables or views. The index provides a fast way to look up data based on the values within those columns. For example, if you create an index on the primary key and then search for a row of data based on one of the primary key values, SQL Server first finds that value in the index, and then uses the index to quickly locate the entire row of data. Without the index, a table scan would have to be performed in order to locate the row, which can have a significant effect on performance.
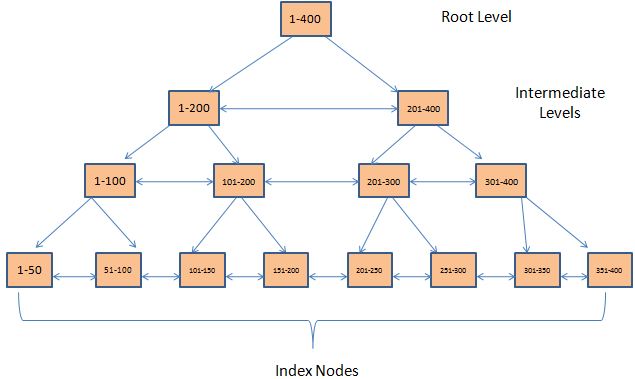
Clustered Indexes
A clustered index stores the actual data rows at the leaf level of the index. Returning to the example above, that would mean that the entire row of data associated with the primary key value of 123 would be stored in that leaf node. An important characteristic of the clustered index is that the indexed values are sorted in either ascending or descending order. As a result, there can be only one clustered index on a table or view.
Nonclustered Indexes
Unlike a clustered indexed, the leaf nodes of a non-clustered index contain only the values from the indexed columns and row locators that point to the actual data rows, rather than contain the data rows themselves. This means that the query engine must take an additional step in order to locate the actual data.
Also See:
SQL Server Index Basics
11.
What are different types of Joins?
Suppose we have two tables A & B:
Table A
| A |
|---|
| 1 |
| 2 |
| 3 |
| 4 |
Table B
| B |
|---|
| 3 |
| 4 |
| 5 |
| 6 |
INNER JOIN
It returns all rows from multiple tables where the join condition is met.
Syntax of SQL Server INNER JOINS
SELECT columns FROM table1 INNER JOIN table2 ON table1.column = table2.column;Using Inner Join on tables A & B result will be:
| A | B |
|---|---|
| 3 | 3 |
| 4 | 4 |
LEFT OUTER JOIN
It returns all rows from the LEFT table specified in the ON condition and only those rows from the other table where the join condition is met.
Syntax of SQL Server LEFT OUTER JOIN
SELECT columns FROM table1 LEFT [OUTER] JOIN table2 ON table1.column = table2.column;Using Left Outer Join on tables A & B result will be:
| A | B |
|---|---|
| 1 | Null |
| 2 | Null |
| 3 | 3 |
| 4 | 4 |
RIGHT OUTER JOIN
It returns all rows from the RIGHT table specified in the ON condition and only those rows from the other table where the join condition is met.
Syntax of SQL Server RIGHT OUTER JOIN
SELECT columns FROM table1 RIGHT [OUTER] JOIN table2 ON table1.column = table2.column;Using Right Outer Join on tables A & B result will be:
| A | B |
|---|---|
| 3 | 3 |
| 4 | 4 |
| Null | 5 |
| Null | 6 |
FULL OUTER JOIN
It returns all rows from the LEFT table and RIGHT table with nulls in place where the join condition is not met.
Syntax of SQL Server FULL OUTER JOIN
SELECT columns FROM table1 FULL [OUTER] JOIN table2 ON table1.column = table2.column;Using Full Outer Join on tables A & B result will be:
| A | B |
|---|---|
| 1 | Null |
| 2 | Null |
| 3 | 3 |
| 4 | 4 |
| Null | 5 |
| Null | 6 |
12.
What is the difference between a Function and a Stored Procedure?
Functions must always return value to the caller. On the other hand stored procedures do not have this requirement. You commonly use functions within another expression, whereas you often use stored procedures independently. [Microsoft SQL Server 2008 For Dummies By Mike Chapple]
Also See:
Difference between a Function and a Stored Procedure
13.
What are Primary Keys and Foreign Keys?
A primary key constraint is a column or a set of columns that uniquely identify a row in the table.
A foreign key constraint consists of a column or a set of columns that participates in a relationship with a primary key table. The primary key is on the one side of the relationship, whereas the foreign key is on the many side of the relationship. A table can have only one primary key, but it can have multiple foreign keys. Each foreign key relates to a different primary key in a separate table. [Sams Teach Yourself SQL Server 2005 Express in 24 Hours By Alison Balter]
Also See:
Difference between Primary Keys and Foreign Keys
14.
What is the difference between Clustered and a Non-clustered Index?
Clustered Index
Only one per table
Faster to read than non clustered as data is physically stored in index order
Non Clustered Index
Can be used many times per table
Quicker for insert and update operations than a clustered index
Both types of index will improve performance when select data with fields that use the index but will slow down update and insert operations. Because of the slower insert and update clustered indexes should be set on a field that is normally incremental ie Id or Timestamp.
SQL Server will normally only use an index if its selectivity is above 95%.
Also See:
Difference between Clustered and a Non-clustered Index
Difference between Clustered and a Non-clustered Index
15.
What’s the difference between a Primary Key and a Unique Key?
Primary Key:
There can only be one primary key in a table.
In some DBMS it cannot be NULL - e.g. MySQL adds NOT NULL.
Primary Key is a unique key identifier of the record.
Unique Key:
Can be more than one unique key in one table.
Unique key can have null values.
It can be a candidate key.
Unique key can be null and may not be unique.
Also See:
Difference between a Primary Key and a Unique Key
Difference between a Primary Key and a Unique Key
16.
What is difference between DELETE and TRUNCATE Commands?
| Truncate | Delete |
|---|---|
| After Truncate, Rollback is not possible. | We can Rollback after Delete. |
| Its DDL | Its DML |
| Can't use WHERE clause with truncate | Can use WHERE clause with Delete |
| Syntax:Truncate Table Table_Name | Syntax:Delete From Table_Name |
Also see:
Difference between Truncate / Delete
Difference between Truncate / Drop
17.
What is the difference between a HAVING clause and a WHERE clause?
HAVING is used to check conditions after the aggregation takes place.
WHERE is used before the aggregation takes place.
This code:
select City, CNT=Count(1) From Address Where State = 'MA' Group By CityGives you a count of all the cities in MA.
This code:
select City, CNT=Count(1) From Address Where State = 'MA' Group By City Having Count(1)>5Gives you the count of all the cities in MA that occur 6 or more times.
[Source]
Also See:
Difference between a HAVING clause and a WHERE clause
18.
What is the difference between UNION and UNION ALL?
UNION removes duplicate records (where all columns in the results are the same), UNION ALL does not. There is a performance hit when using UNION vs UNION ALL, since the database server must do additional work to remove the duplicate rows, but usually you do not want the duplicates (especially when developing reports). [Source]
Also See:
Difference between UNION and UNION ALL
19.
What is an Identity?
When you make a column an identity column, SQL Server automatically assigns a sequenced number to this column with every row you insert. The number that SQL Server starts counting from is called the seed value, and the amount that the value increases or decreases by with each row is called the increment. The default is for a seed of 1 and an increment of 1. Once you have set a seed (the starting point) and the increment, your values only go up (or down if you set the increment to a negative number). There is no automatic mechanism to go back and fill in the numbers for any rows you may have deleted. If you want to fill in blank spaces like that, you need to use SET IDENTITY_INSERT ON, which allows you to turn off the identity process for inserts from the current connection. [Beginning Microsoft SQL Server 2012 Programming By Paul Atkinson, Robert Vieira]
Also See:
Identity
20.
What is CHECK Constraint?
A check constraint limits the values allowed in a column.
Example
CREATE TABLE MyOrders (OrderID INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, Amount DECIMAL(18,2), Tax DECIMAL(5,2) CHECK (Tax >= 0.0 AND Tax <= 200.0) )
Now when you try inserting data:
INSERT INTO MyOrders(Amount, Tax) VALUES (150.0, 2.75) INSERT INTO MyOrders(Amount, Tax) VALUES (250.0, 15.75) INSERT INTO MyOrders(Amount, Tax) VALUES (300.0, 210.0)
The first two insert statements will just work fine but the third statement will give below error:
Msg 547, Level 16, State 0, Line 1 The INSERT statement conflicted with the CHECK constraint "CK__Orders__Tax__2BFE89A6". The conflict occurred in database "new_DB", table "dbo.Orders", column 'Tax'. The statement has been terminated.
Also See:
Check Constraint
21.
How to delete duplicate rows?
Below are two ways to delete duplicate records from a table in SQL Server:
Suppose we have a table P as shown below:
Select * from P
| ID | Name |
|---|---|
| -100 | AA |
| -1100 | BB |
| -2100 | CC |
| -100 | AA |
This query deletes all the duplicate rows:
DELETE FROM P WHERE ID IN ( SELECT MIN(ID) FROM P GROUP BY ID, Name having count(*)>1)Result after running the above query:
Select * from P
| ID | Name |
|---|---|
| -1100 | BB |
| -2100 | CC |
Lets again use our table P and see second method of deleting duplicate rows from a table:
Select * from P
| ID | Name |
|---|---|
| -100 | AA |
| -1100 | BB |
| -2100 | CC |
| -100 | AA |
This query deletes all duplicate rows but one. For example if you have two same rows in a table it deletes one and keeps the other.
WITH cte AS (
SELECT ID, Name,
row_number() OVER(PARTITION BY ID, Name ORDER BY ID) AS [rn]
FROM P
)
DELETE cte WHERE [rn] > 1
Results of running the above query:Select * from P
| ID | Name |
|---|---|
| -100 | AA |
| -1100 | BB |
| -2100 | CC |
Also See:
Deleting duplicate records
22.
What is NOT NULL Constraint?
NOT NULL constraint is a type of a check constraint because it checks that a column value is set to something and not specifically set to NULL.
Also See:
NOT NULL Constraint
23.
What are user-defined functions? What are the types of user-defined functions that can be created?
Like functions in programming languages, SQL Server user-defined functions are routines that accept parameters, perform an action, such as a complex calculation, and return the result of that action as a value. The return value can either be a single scalar value or a result set.
Scalar Function
User-defined scalar functions return a single data value of the type defined in the RETURNS clause.
Example
CREATE FUNCTION MyReverse1(@string varchar(100))
RETURNS varchar(100)
AS
BEGIN
DECLARE @custName varchar(100) =''
SET @custName = Reverse (@string)
RETURN @custName
END
Call the above function as Select dbo.MyReverse1('SQL');
Result:
| (No column name) |
|---|
| LQS |
Table-Valued Functions
User-defined table-valued functions return a table data type.
Example
CREATE FUNCTION SalaryMoreThan(@Sal INT)
RETURNS TABLE
AS
RETURN
SELECT Id, Name, Salary
FROM teacher
WHERE Salary > @Sal
SELECT Id, Name, Salary
FROM SalaryMoreThan(200) System Functions
SQL Server provides many system functions that you can use to perform a variety of operations. They cannot be modified.
Also See:
User-defined functions
24.
Which TCP/IP port does the SQL Server run on? How can it be changed?
SQL Server runs on port 1433. It can be changed from the Network Utility TCP/IP properties.
25.
What is a Table Called, if it has neither Cluster nor Non-cluster Index? What is it used for?
Its heap and it is used for inserting and updating records.
26.
What is the difference between CHAR and VARCHAR Datatypes?
The primary difference between the varchar and char types is data padding. If you have a column called FirstName that is a varchar(10) data type and you store the value of "SAM" in the column, only 3 bytes are physically stored, plus a little overhead. If you store the same value in a char(10) data type, all 10 bytes would be used. SQL inserts trailing spaces to fill the 10 characters.
Example depicting the difference between CHAR and VARCHAR
DECLARE @Var_Char Char(10) = 'SAM', @Var_Varchar VarChar(10) = 'SAM' SELECT DATALENGTH(@Var_Char) Char_Space_Used, DATALENGTH(@Var_Varchar) VarChar_Space_Used
| Char_Space_Used | VarChar_Space_Used |
|---|---|
| 10 | 3 |
Another good source of difference between CHAR and VARCHAR.
Also See:
Professional Microsoft SQL Server 2014 Administration by Adam Jorgensen, Bradley Ball, Steven Wort, Ross LoForte, Brian Knight
27.
What is the difference between VARCHAR and NVARCHAR datatypes?
The difference is that nvarchar data types can be used for unicode data that can store data in any language whereas varchar data types cannot store data an all languages. So if you need your application to be truly international it is best to use nvarchar data types. [Source: Practical Sql: Microsoft Sql Server T-SQL for Beginners by Mark O'Donovan]
The main difference between the VARCHAR and the NVARCHAR data types is that each NVARCHAR character is stored in 2 bytes, while each VARCHAR character uses 1 byte of storeage space. The maximum number of characters in a column of NVARCHAR data type is 4000. [Source: Microsoft SQL Server 2012 A Begineers Guide by PETKOVIC]
28.
Why can there be only one Clustered Index and not more than one?
The leaf level of a clustered index is the table itself. The clustered index sits on the top of the table. As a result, the table is physically sorted according to the clustered key. For this reason, a table can have only one clustered index. [Building Client-Server Applications with Visual FoxPro and SQL Server 7. 0 by Chuck Urwiler, Gary DeWitt, Leslie Koorhan, Mike Levy]
The reason why there can be only one clustered index on a table is that the clustered index governs the physical placement of the data, and the data cannot be in two places at once. There can only be one sequence in which the data can be physically placed. [Microsoft SQL Server 2005 Performance Optimization and Tuning Handbook by Ken England, Gavin JT Powell]
29.
How to copy data from one table to Another Table?
If both tables are truly the same schema:
INSERT INTO newTable
SELECT * FROM oldTable
Otherwise, you'll have to specify the column names (the column list for newTable is optional if you are specifying a value for all columns and selecting columns in the same order as newTable's schema):
INSERT INTO newTable (col1, col2, col3)
SELECT column1, column2, column3
FROM oldTable
[Source]
30.
How to find the second highest salary from a table?
CREATE TABLE EMP (
EMP_ID int,
Salary int
);
Insert into EMP values (1, 200);
Insert into EMP values (2, 100);
Insert into EMP values (3, 50);
Insert into EMP values (4, 600);
Insert into EMP values (5, 300);
Select * from EMP| EMP_ID | Salary |
|---|---|
| 1 | 200 |
| 2 | 100 |
| 3 | 50 |
| 4 | 600 |
| 5 | 300 |
Example 1 of Finding the 2nd highest salaryResult:
--Second highest Salary SELECT max(Salary) FROM EMP WHERE Salary < (SELECT max(Salary) FROM EMP);
| (No column name) |
|---|
| 300 |
Example 2 of Finding the 2nd highest salaryResult:
--Nth highest salary SELECT TOP 1 Salary FROM ( SELECT TOP 2 Salary FROM EMP ORDER BY Salary DESC) AS EMP ORDER BY Salary ASC
| Salary |
|---|
| 300 |